数据结构 From Zero To Hero(一)
本篇开始,我们重新学习一下数据结构。这次,不仅仅是概念上的学习,而且会使用代码来实现每个数据结构以及对应的常用操作。
复杂度分析的意义
执行效率是评价算法好坏的一个非常重要的指标,衡量算法的执行效率最重要的两个方面就是:
- 时间复杂度
- 空间复杂度
我们将代码运行一遍,通过监控和统计就可以得到执行时间和占用内存。为什么还需要复杂度分析呢。实际上这是两种评估方法,运行代码来统计复杂度的方法称为事后统计法。它存在一些局限性:
- 测试结果受测试环境影响大
- 测试结果受测试数据影响大
大 O 复杂度表示法
大 O 表示法并不具体表示代码真正的执行时间,而是表示代码执行时间随着数据规模增大的变化趋势。简称时间复杂度。
当 n 很大时,公式中低阶、常量、系数三部分并不左右增长趋势,因此可以忽略。我们只需记录一个最大量级。
时间复杂度的分析方法
有两个比较实用的法则可以帮助我们进行时间复杂度的分析:
- 加法法则: 代码总的复杂度等于量级最大的那段代码的复杂度
- 乘法法则: 嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
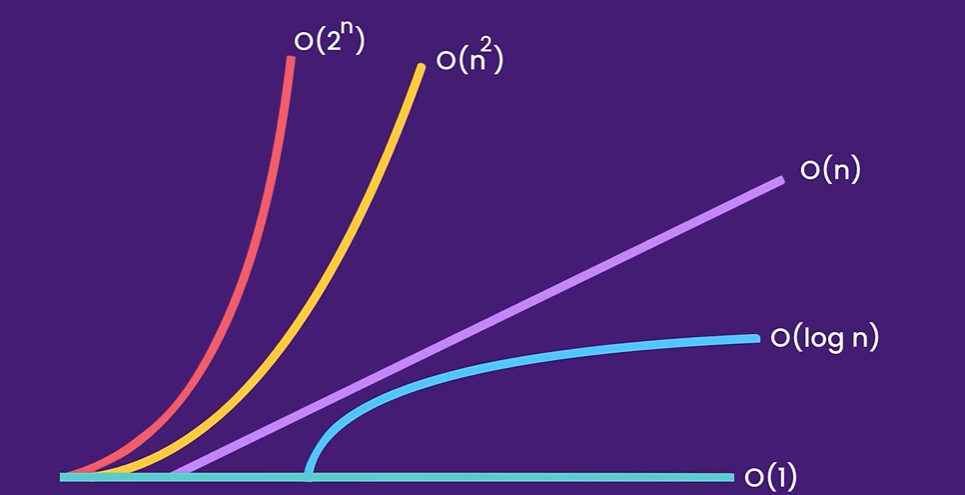
常见时间复杂度量级
- O(1): 只要代码的执行时间不随数据规模变化,代码就是常量级时间复杂度,统一记作 O(1)
- O(logn)、O(nlogn): 无论以任何常数为底,对于对数阶时间复杂度,统一表示为 O(logn)
- O(m+n)、O(mn): 当代码的时间由两个数据规模决定,我们不能忽略任何一个,都要保留
空间复杂度分析方法
空间复杂度与时间复杂度类似,如果申请的空间与数据规模无关,那么空间复杂度就是 O(1)。常见的空间复杂度有: O(1)、O(n)、O(n2)、O(logn) 和 O(nlogn)。
最坏、最好时间复杂度
我们用一个示例来理解最好和最坏时间复杂度:
|
上面是数组中查找一个元素的位置,实际中,我们并不一定需要遍历一遍,也有可能提前退出。我们对上面代码进行优化:
|
为了表示代码在不同情况下的时间复杂度,引入三个概念: 最坏时间复杂度、最好时间复杂度和平均时间复杂度。
上面示例中,最好的情况是数组中第一个元素就是要查找的元素,那么最好时间复杂度是 O(1)。最坏的情况是遍历一遍才找到或者数组中不存在该元素,那么最坏时间复杂度是 O(n)。
平均时间复杂度
为了更好的表示平均情况下的复杂度,我们引入平均时间复杂度。上面的示例中平均时间复杂度计算过程是: (1+2+3+..n+n)/(n+1) = n(n+3)/2(n+1)。忽略系数、低阶和常量,简化后表示为 O(n)。